
记一次线上服务每10分钟有大量对象集中进入到老年代空间
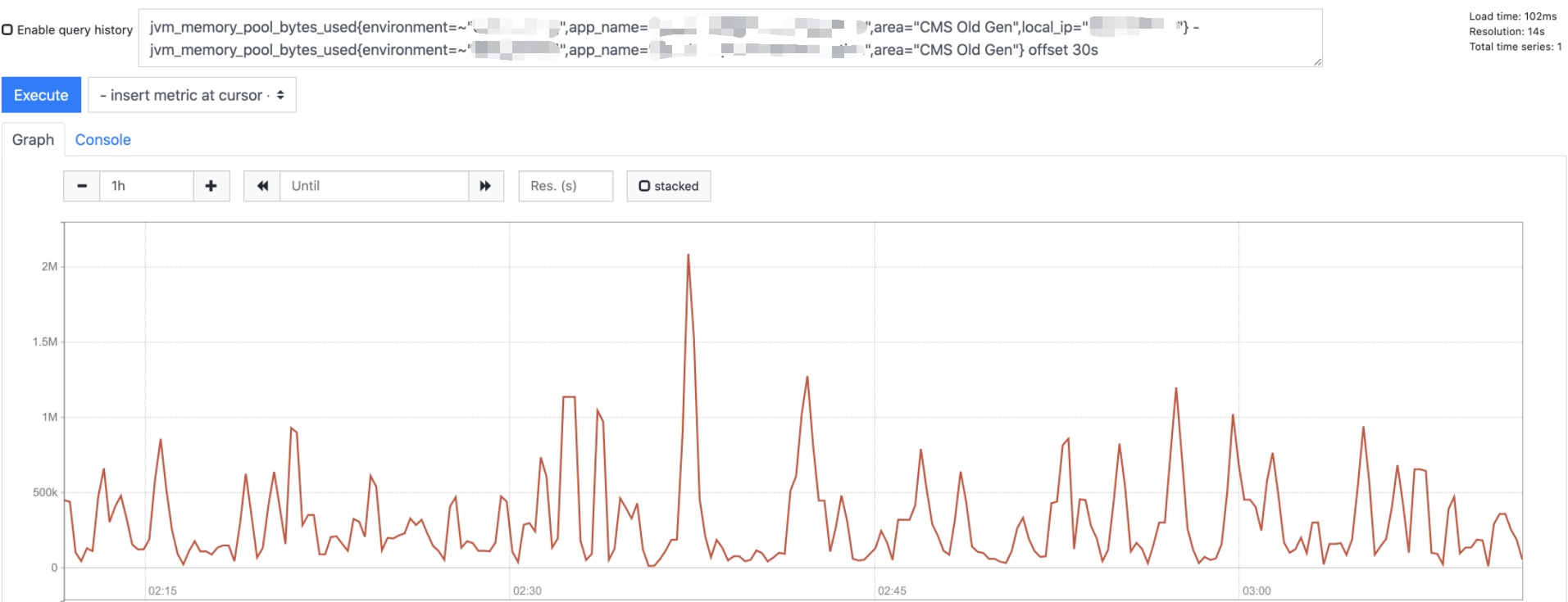
观察线上某个服务监控发现老年代每10分钟有明显增长,截图如下:
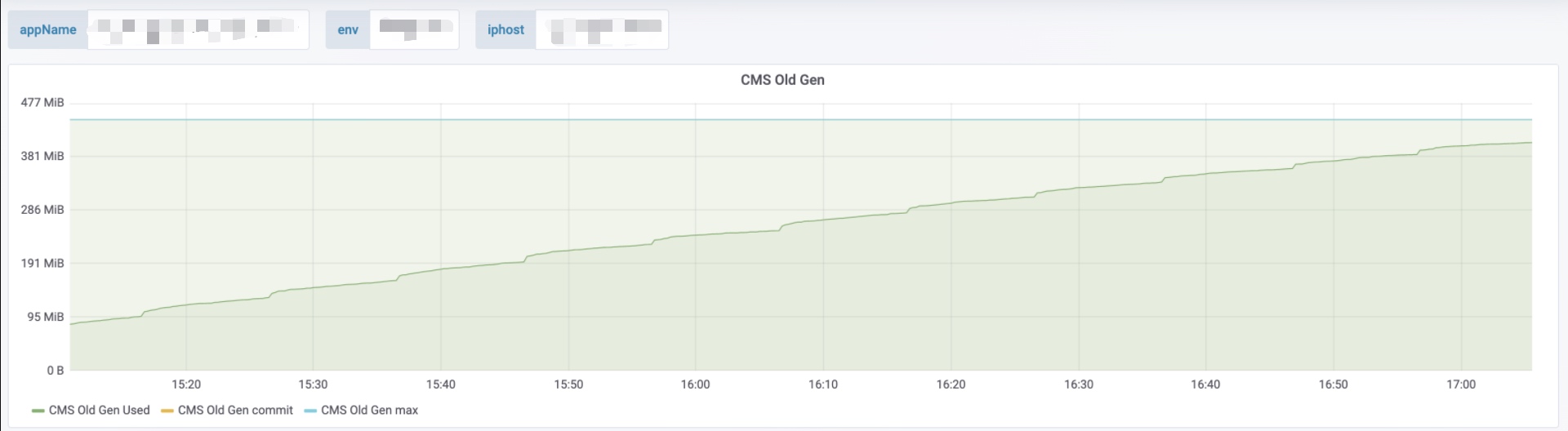
这个监控的图看上去不太直观,转到监控页,将上面的图转换为Y轴的增长图如下: 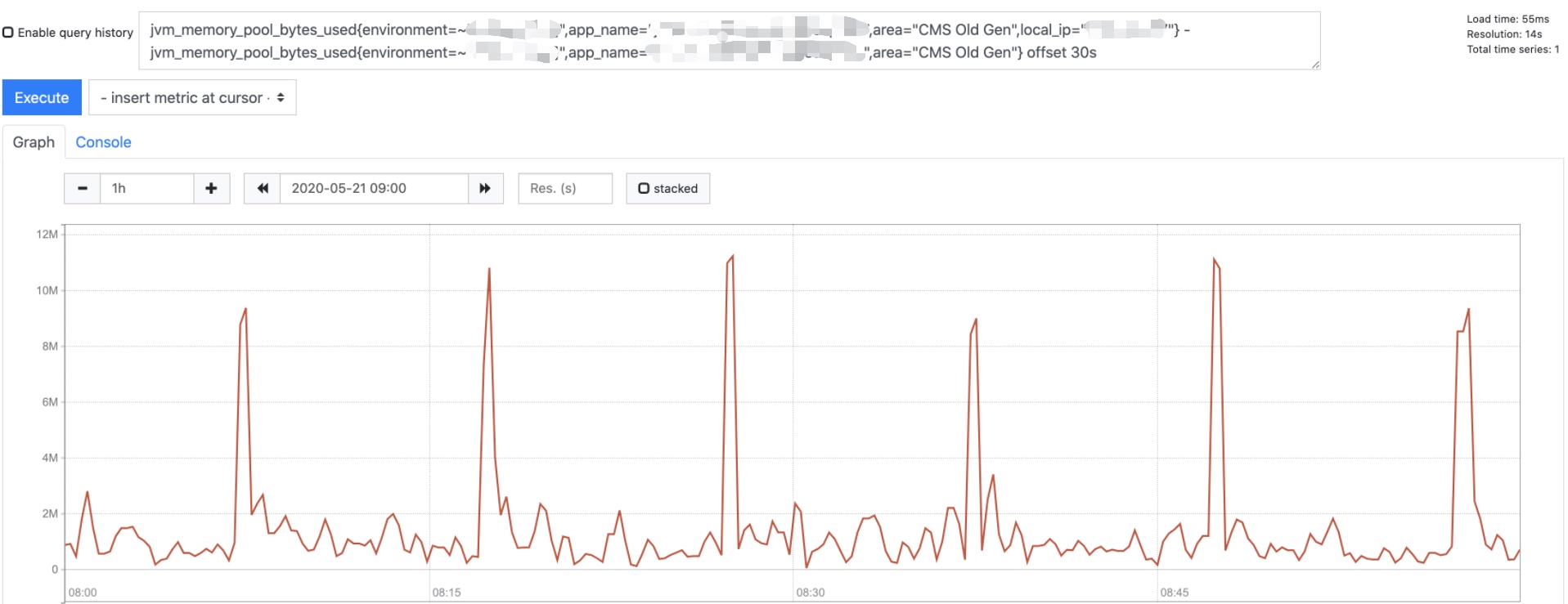
查看临近内存增长峰尖的gc日志发现确实存在一部分数据由于达到MaxTenuringThreshold(CMS默认为6)晋升到老年代。 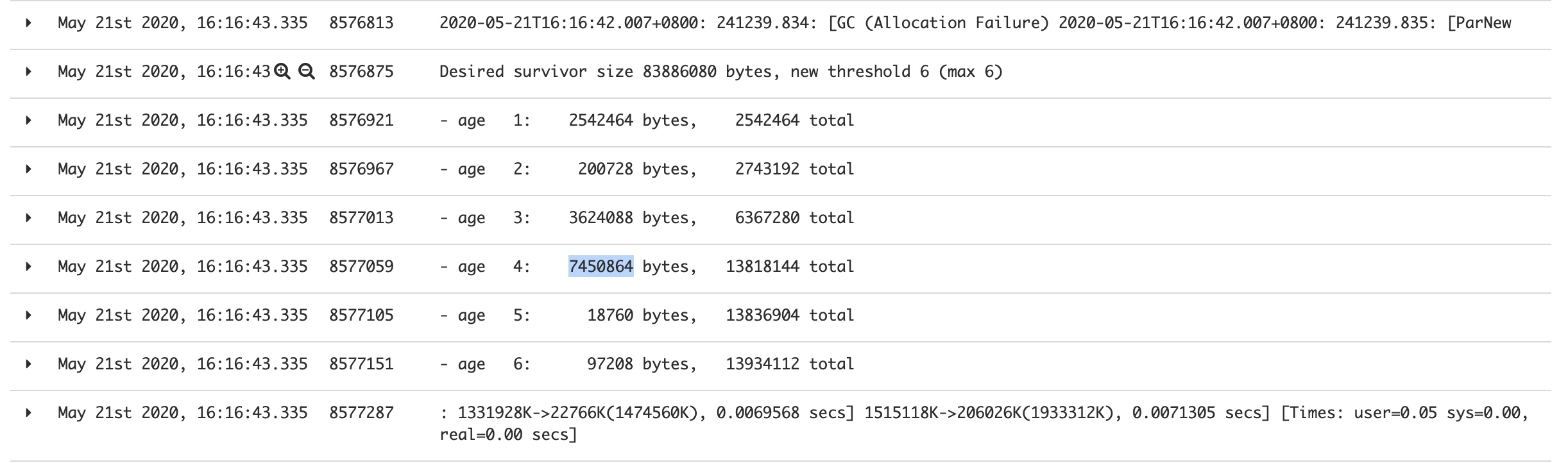
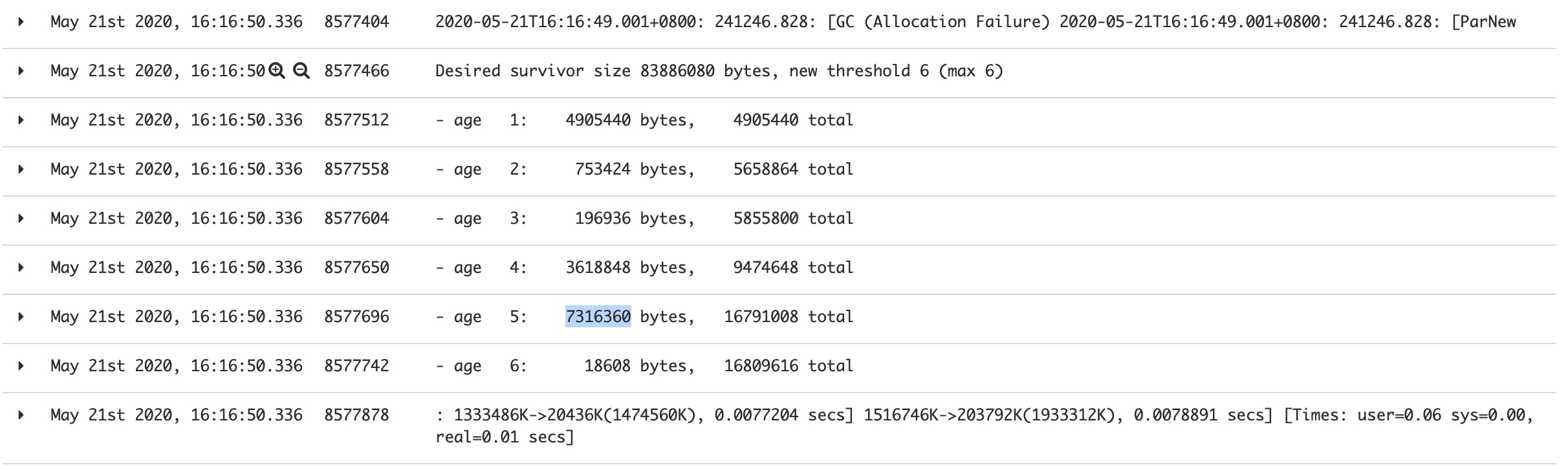
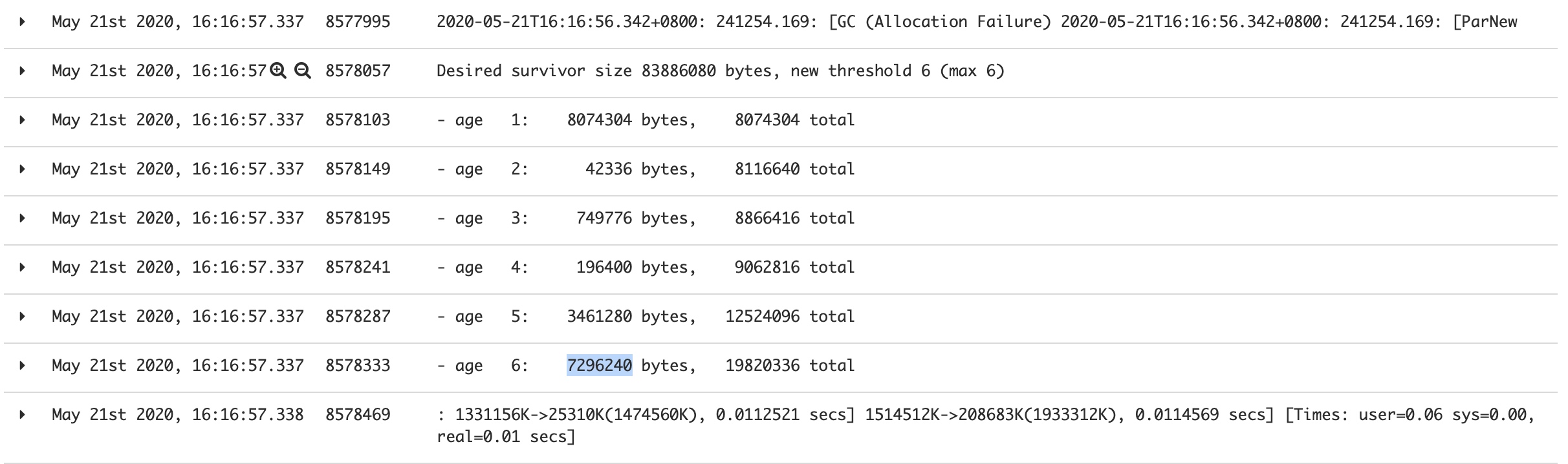
于是第一时间想到调整MaxTenuringThreshold这个值到最大值15,结果这部分对象很牛逼撑过了15次YGC晋升到老年代,┓( ´∀` )┏
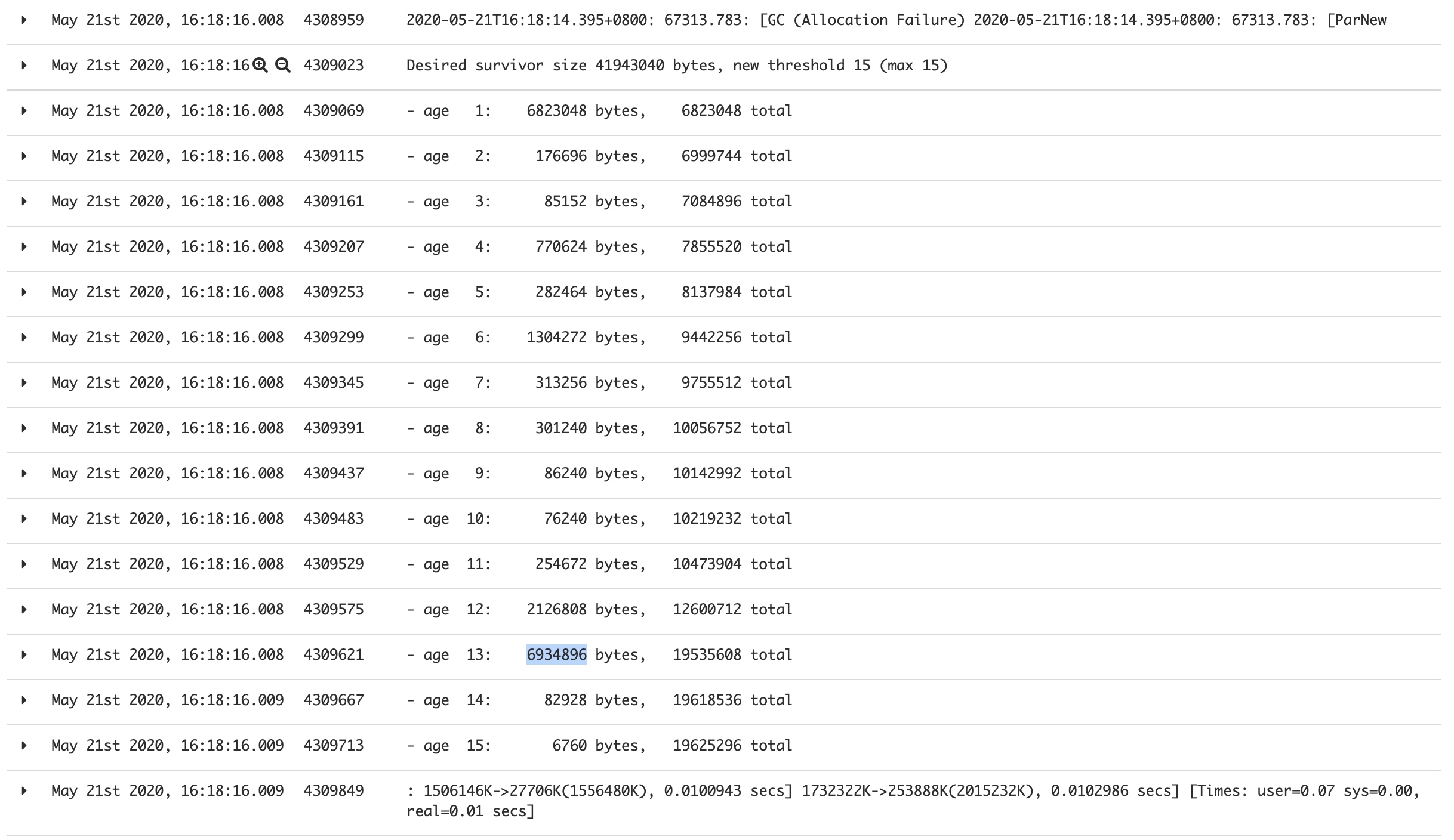
说明此路不通,但这个服务只通过http对外提供服务,且内部没有定时任务,说明可能是使用的框架或者什么组件导致了这个现象,于是想到抓一个heapdump分析到底进入到老年代的对象都是些啥(注意:这里需要一个fulldump,jmap -dump:format=b,file=<file> <pid>)
拿到dump,通过MAT分析,结果如下: 
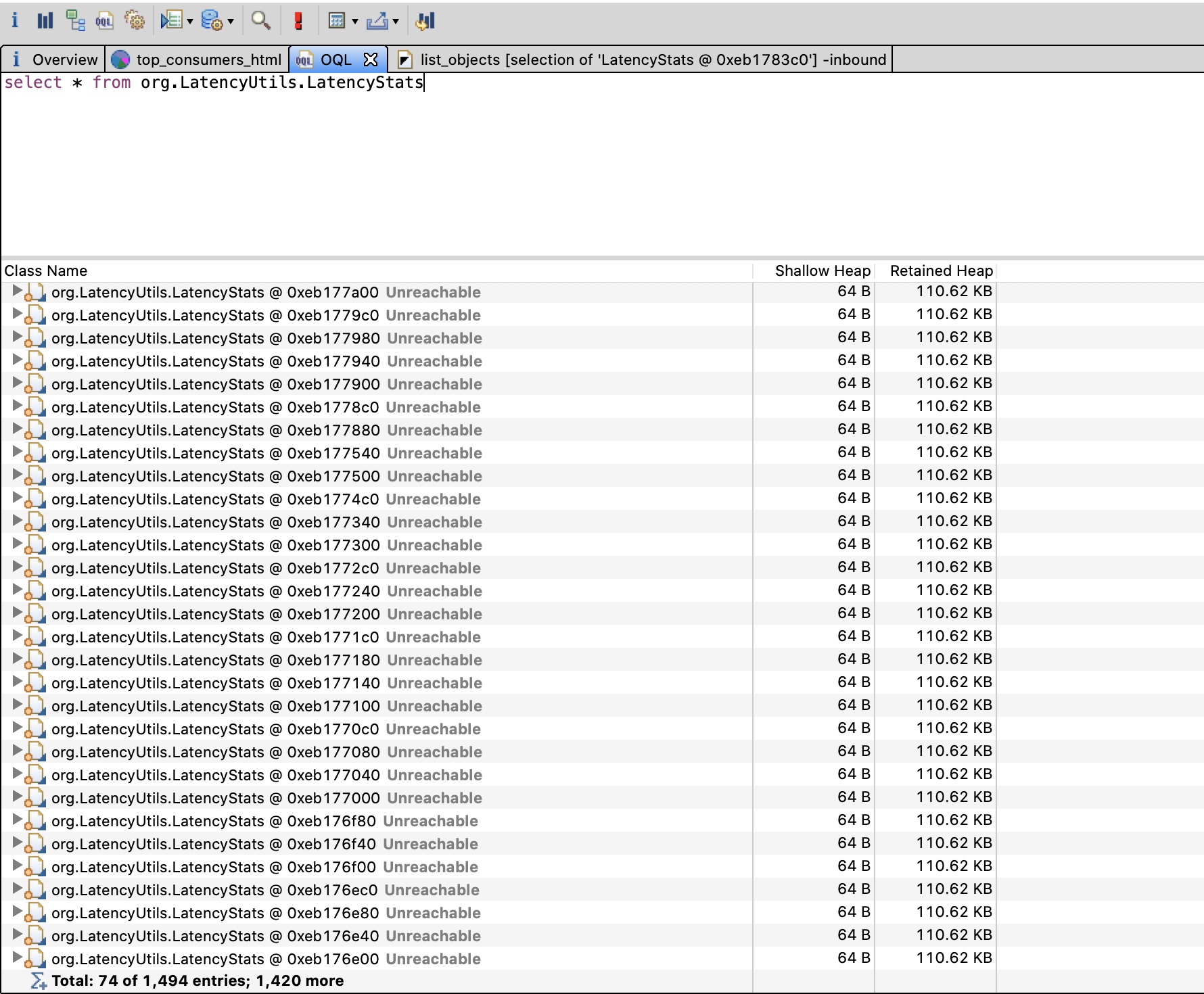 有一个包名包含LatencyUtils的类
有一个包名包含LatencyUtils的类org.LatencyUtils.LatencyStats很可疑,竟然总共占用了160m的堆内存空间,于是分析项目代码,最终定位到这些大量的对象来自于lettuce(基于netty的redis客户端)命令延迟监控功能(io.lettuce.core.metrics.DefaultCommandLatencyCollector),这个命令延迟监控的数据默认每10分钟通过lettuce的eventBus吐给客户端应用。通过查看lettuce的文档可以验证这一点: 
再进一步查看lettuce源码发现这个命令延迟记录的功能虽是默认开启,但也依赖于LatencyUtils组件,所以如果运行时classpath中不包含这个组件的话,这个功能会被禁用,那么通过gradle分析一下这个组件是怎么引入进来的即可:
$ ./gradlew :base
—dependency org.latencyutils > Task :base org.latencyutils:LatencyUtils:2.0.3 variant “runtime” [ org.gradle.status = release (not requested) Requested attributes not found in the selected variant: org.gradle.usage = java-api ] --- co.paralleluniverse:quasar-core:0.7.9 --- compileClasspath A web-based, searchable dependency report is available by adding the —scan option. BUILD SUCCESSFUL in 1s 1 actionable task: 1 executed
通过上面输出可以看到由于在classpath中引入了co.paralleluniverse:quasar-core导致其依赖也被引入了进来,其中就包含LatencyUtils组件,由于历史原因,这个quasar-core的包已经不再使用了,但其依赖没有被删除,于是导致了我们看到的问题。 解决办法就简单了,既然不再需要删除上面这个依赖就好了。 上线后再观察监控,现象已经没了。
参考资料